In October 2025, the Cancer AI Alliance (CAIA) announced the launch of the first scalable platform using federated learning for cancer research.
CAIA is comprised of National Cancer Institute-designated cancer centers Dana-Farber Cancer Institute, Fred Hutch Cancer Center, Memorial Sloan Kettering Cancer Center, and The Sidney Kimmel Comprehensive Cancer Center and Whiting School of Engineering at Johns Hopkins with financial and technological support from technology industry leaders Amazon Web Services (AWS), Deloitte, Ai2 (Allen Institute for AI), Google, Microsoft, NVIDIA and Slalom.
This federated learning platform is the technological foundation that will enable researchers and clinicians to train AI models that learn from our participating cancer centers’ millions of clinical data points while maintaining data security, privacy and adherence to regulatory and ethical standards.
Federated Learning in Cancer Research
A complete guide to how the Cancer AI Alliance (CAIA) uses federated learning to advance cancer research and enable cross-institutional collaboration.

Table of contents: Federated learning in cancer research
What is federated learning?
Federated learning is an AI training approach and machine learning method that preserves the anonymity of individual data. Within the context of the Cancer AI Alliance, this approach allows researchers and clinicians to train powerful AI models that learn from participating cancer centers' millions of clinical data points while maintaining data security, privacy, and adherence to regulatory and ethical standards.
Instead of bringing sensitive patient data to a centralized location, federated learning brings the AI model to the data. The AI models travel to each participating cancer center’s secure data to learn from it locally. Patient data remains safely behind institutional firewalls, and individual clinical data never leaves the institution.
How does federated learning work?
Federated learning lets researchers improve AI models using data from multiple institutions without sharing sensitive information. First, a researcher sends their AI model to a central orchestration layer. This layer then sends the model to different cancer centers to analyze their local de-identified data. The result of that analysis (but not the underlying data itself) are combined and sent back to the central system. This process repeats multiple times to refine the model, and finally, the improved model is returned to the original researcher, all without accessing identifiable patient data, and without any raw patient data ever leaving its home institution
Why is data federation useful in cancer research?
Data federation, as implemented by CAIA, is a framework aimed at aggregating AI insights across a distributed network of cancer centers without compromising patient data, privacy, or security. CAIA’s data federation framework is underpinned by an AI training approach called federated learning.
Data federation fosters greater diversity in cancer research. Individual cancer centers only have information about patients who come to their clinics for treatment. Thus, models developed on data from a single institution are only able to learn about that subset of the population. This limits their models from being generalizable.
Data federation in cancer research can overcome this limitation by enabling groups of researchers and institutions to work together with a more diverse data set. The key idea that led to the creation of the Cancer AI Alliance is that if cancer centers work together, then we can make demonstrable progress to accelerate treatments and cures.
Lastly, data federation enables scalability and ease of expansion. Unlike centralized data projects that face massive logistical hurdles when adding new partners, CAIA’s federated network is designed for expansion. Each participating institution’s data source can be added to the federated framework as an additional edge node.
How does the orchestration layer work?
The central orchestration layer acts like a conductor for an orchestra
The orchestration layer has two primary but inter-related functions:
As a coordinator: By tracking which cancer center is connected and active, ensuring that the cancer center is operating as expected and ready to receive model weights and summaries from CAIA.
As an aggregator: It takes the updated model weights (summarized insights) sent back from the cancer centers and combines them to create a stronger, more generalized global model.
The CAIA platform leverages NVIDIA FLARE (which stands for Federated Learning Application Run-time Environment), an open-source library that provides a framework to control the communication between components of the federated network.
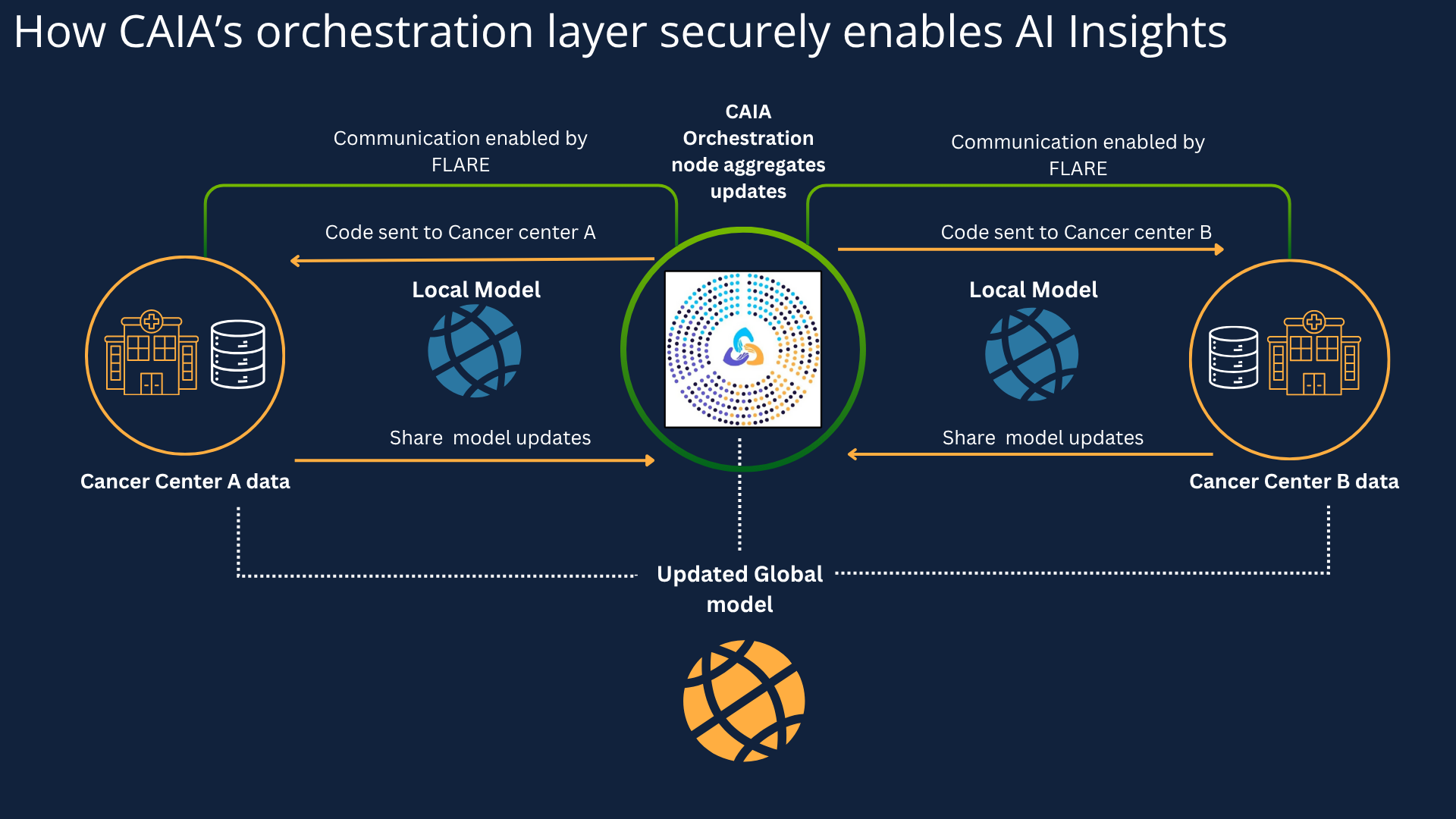
Does the orchestration layer see the patient data?
No, the orchestration sends the AI model and instructions to each of the edge nodes (at the cancer centers) but never sees the patient data.
The orchestration layer can neither access the cancer centers’ data nor independently initiate contact; it relies on the cancer centers to establish a secure connection. Each of the cancer centers receives a piece of the FLARE-based software package that polls the orchestrator for tasks and executes those tasks locally. Each cancer center must actively connect to the central orchestration layer.
The CAIA orchestration layer makes privacy-preserving cancer research possible at scale. By serving as both a coordinator and aggregator, it oversees the repeated process of federated learning.
What is an edge node?
Within CAIA’s federated network, each participating cancer center acts as an edge node — a device that is a secure gateway between the cancer center and the rest of the alliance. Patient data remains safely behind a firewall and never leaves the cancer center.
Each edge node connects to the central orchestration layer. The orchestration layer sends the AI model and instructions to each edge node. Each edge node trains the AI model within its own secure environment using its local, secure data. The edge node then sends a summary of its learnings (the updated model), which contains no private patient information, back to the central orchestration layer to be aggregated and strengthen the model.
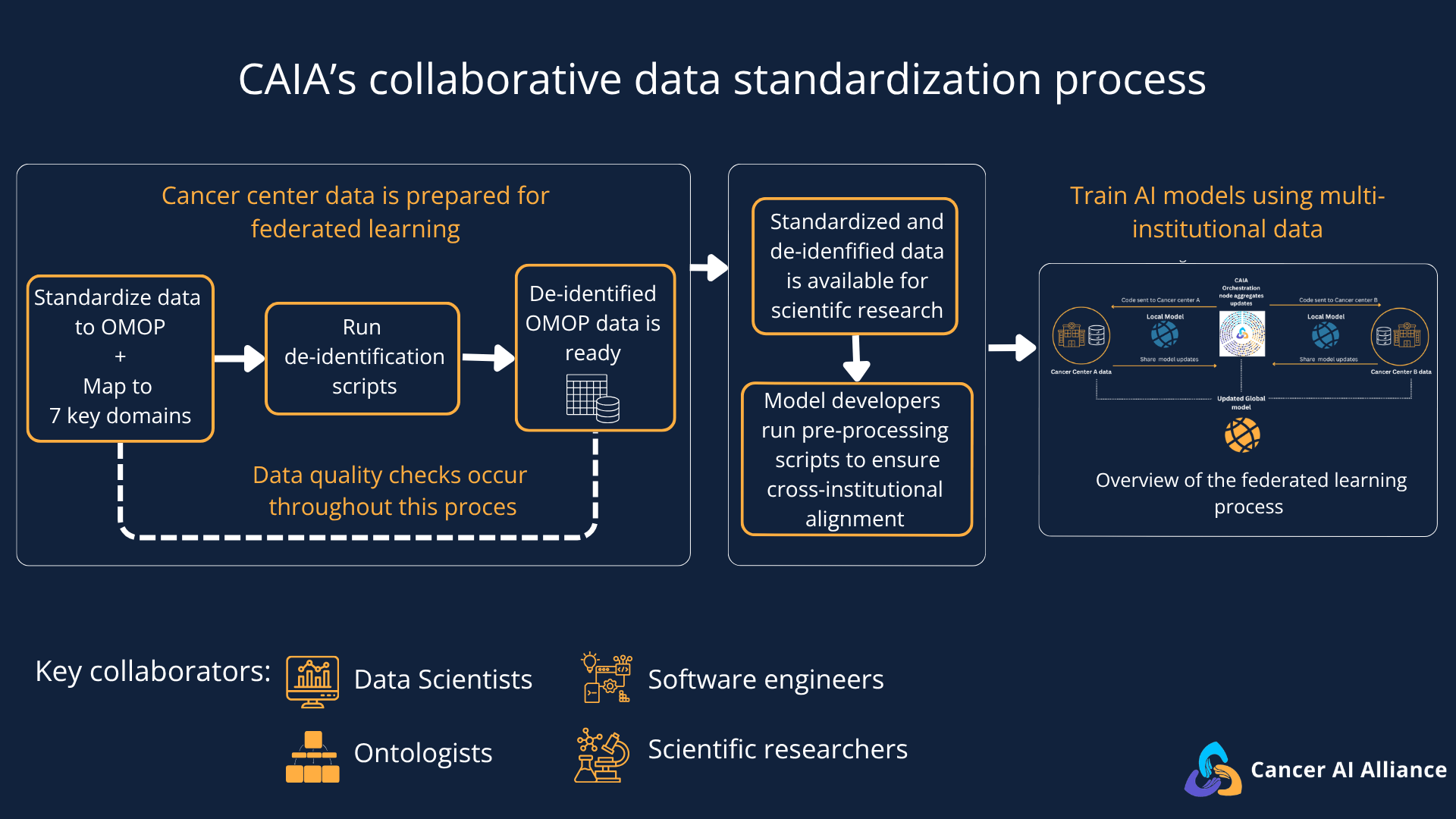
Standardizing data for federated learning in cancer research
Hospitals gather a substantial amount of data on every patient’s health. When a patient visits a cancer center, their experience generates two main types of data:
Structured Data: Clean, organized entries like the dose of a drug or the results of a lab test.
Unstructured Data: Free-text documents like pathology reports or radiology reports
Imagine combining a single patient’s data, with millions of other patient journeys across the country, to create powerful AI models to find new cures.
The key to unlocking this potential is data standardization. This work ensures that the vast amount of information collected during a patient's care can be interpreted, and reliably analyzed across different institutions. In other words, the goal of data standardization is to create a common format that is accessible and useful to researchers for collaborative, multi-institutional cancer discovery.
What is OMOP and how is CAIA using it to standardize data?
CAIA has adopted OMOP (Observational Medical Outcomes Partnership) as its core Common Data Model (CDM). OMOP is an open data community standard that can translate local hospital codes into a universal standardized system, making the data understandable across all sites that share this same data model.
In general, a Common Data Model (CDM) provides a framework for how different types of patient information and codes must be organized and structured. Adopting OMOP as CAIA’s Common Data Model will enable AI models to interpret the collective experience of millions of patients across institutions and provide researchers with standardized data that can be applied in a wide variety of clinical environments.
What are the key benefits of using federated learning?
Federated learning enables a strategic shift leveraging collective strength rather than isolation, accelerating the pace of breakthrough discoveries by up to tenfold.
Healthcare institutions have a number of safeguards and regulations in place to secure patient data. Federated learning allows for collaboration, helping organizations work together across institutional silos and accelerate progress.
Additionally, research conducted at a single center may not translate to other populations. By training across multiple centers on CAIA’s federated learning platform, AI models are more robust and accurate for a wider variety of patients.
The resulting AI models are also more powerful and equitable because they learn from a diverse and representative sample of patients across the country. By combining insights from small patient populations across multiple centers to uncover new patterns and potential therapies.
Why has CAIA prioritized building a federated learning platform?
CAIA is leading a transformation in cancer research by enabling a platform approach across multiple institutions.
CAIA launched its federated learning platform to enable cancer centers to compile and re-use federated datasets, allowing many researchers to answer different types of questions. This is a departure from traditional biomedical research, where protocols are designed to answer one very specific question.
By focusing on this foundational infrastructure, CAIA ensures that the platform can support a multitude of projects simultaneously with federated data across the entire network.
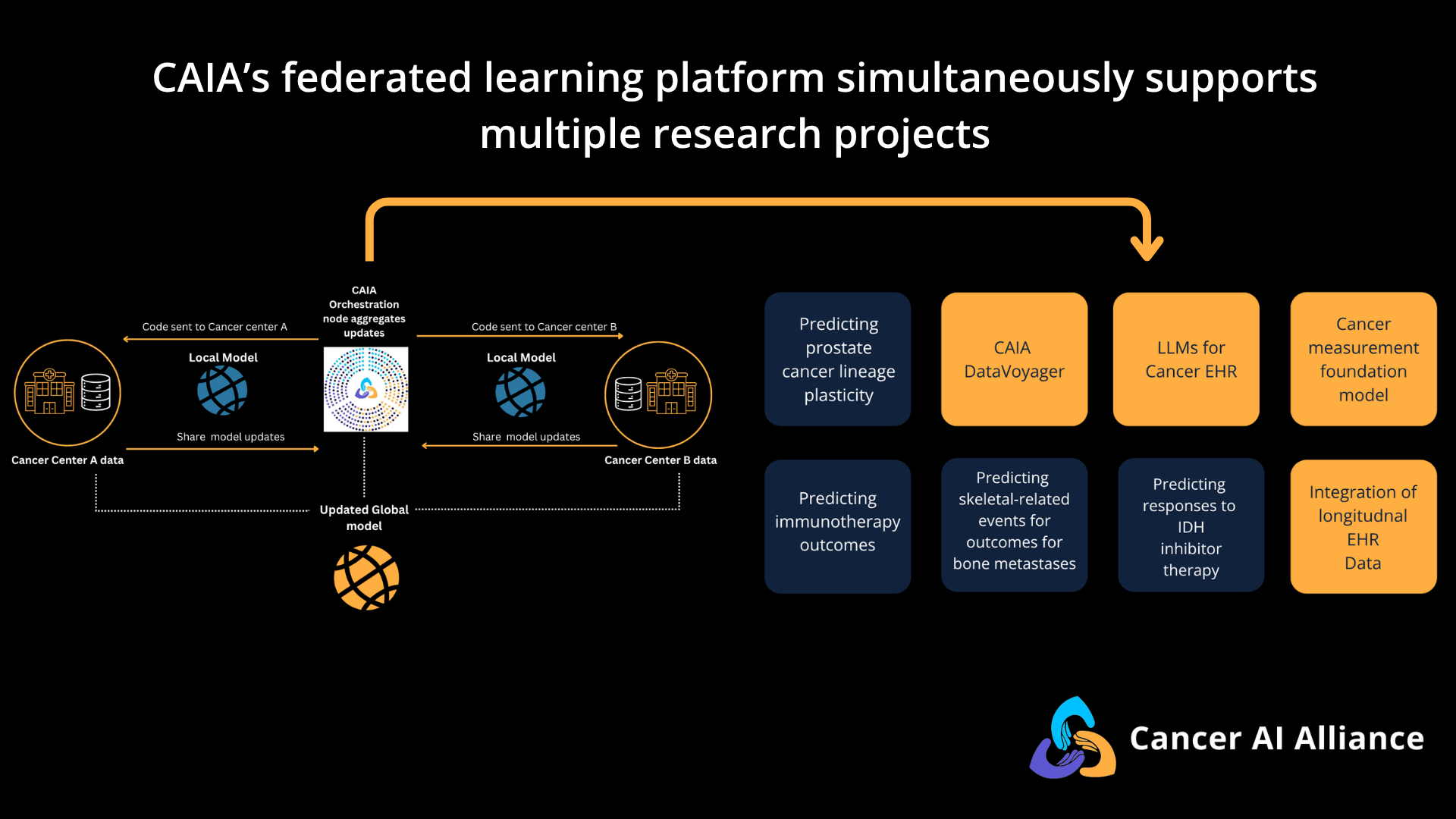
What kinds of projects is CAIA enabling with its federated learning platform?
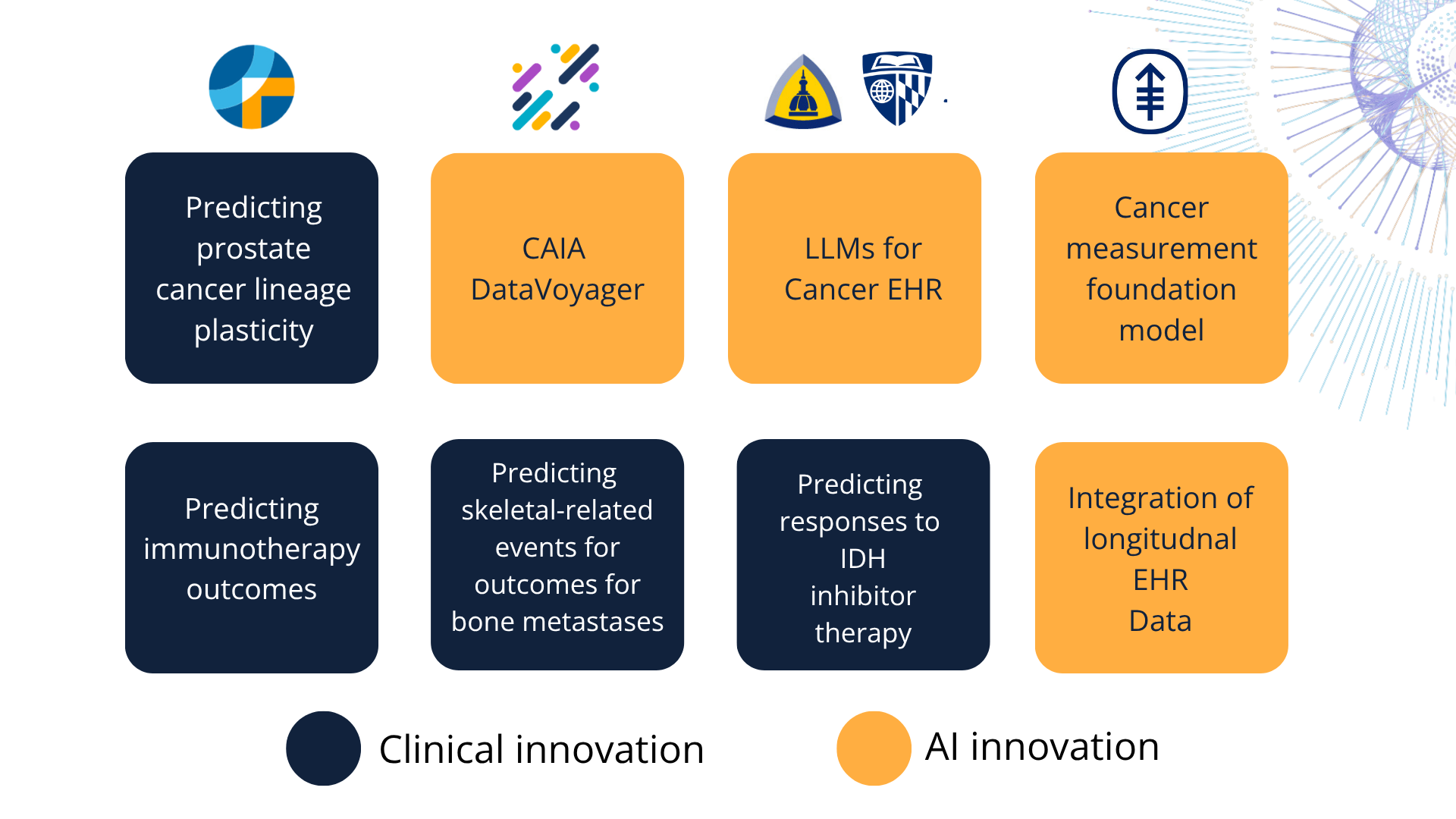
CAIA is currently supporting eight unique pilot projects across our federated network. These projects represent the first wave of our efforts, proving that we can analyze vast amounts of data while keeping patient privacy secure at the local level.
Half of CAIA’s projects are focused on clinical innovation. These use AI to answer critical questions related to patient care today. But they aren't doing it in isolation. By leveraging CAIA’s federated network, researchers can train their models on massive, de-identified datasets spanning multiple institutions. This allows them to spot rare patterns—like what predisposes a patient to severe bone fractures—that a single hospital simply doesn't have the patient volume to sufficiently understand.
The other half of our projects are focused on AI innovation. If clinical innovation is about solving today's problems, AI innovation is about building the infrastructure for tomorrow. Rather than building separate AI models for every type of cancer, these projects are creating the underlying "brains": massive foundation models trained on cross-institutional data. Once these baseline models are built, future researchers can use them as tools to answer many questions based on the patterns captured in the models.
How has CAIA adapted federated learning for multi-institutional cancer research?
While federated learning has been gaining steam for nearly 10 years, adapting the technology for multi-institution use in cancer research has proved elusive due to significant technological, regulatory, patient privacy, and data harmonization challenges, as well as the coordination effort necessary to bring together organizations of this scale and complexity.
CAIA has overcome these barrier by developing federated access models, governance structures, and streamlined regulatory pathways that accelerate multi-institutional AI research.
CAIA’s early commitment to governance and alignment has allowed many organizations to work together for human-centric outcomes, under the organizing principle that cancer is non-partisan, and requires cooperation at a larger scale than before.
This intense focus on security and governance was necessary for building trust among the participating cancer centers.