How CAIA enables cross-organizational research through collaborative data standardization
In a previous post, we outlined how CAIA’s participating cancer centers aligned on using OMOP (Observational Medical Outcomes Partnership) as our Common Data Model (CDM). Adopting OMOP and following the same data standards across participating cancer centers was one of the first key steps in enabling federated learning.
At CAIA, each cancer center acts as an independent “edge node,” keeping de-identified clinical data securely behind their own institutional firewalls. Without data standardization, the AI models trained at each edge node would fail to align, preventing meaningful federated learning.
All the data had to speak the same common language, necessitating the shift to OMOP. Adopting OMOP and following uniform data standards across cancer centers was a crucial step that enabled true cross-organizational collaboration.
In this blog post, we’ll take you behind the scenes of this standardization process, exploring the data mapping and cross-institutional coordination required to make multi-site federated learning work.
Standardization allows data to be more meaningful
AI learns by finding patterns in data — so the more high-quality data it has to work with, the better it gets at making accurate predictions. To train useful AI models that clinicians and researchers can trust, participating cancer centers had to standardize their data without losing the clinical context that makes those data meaningful.
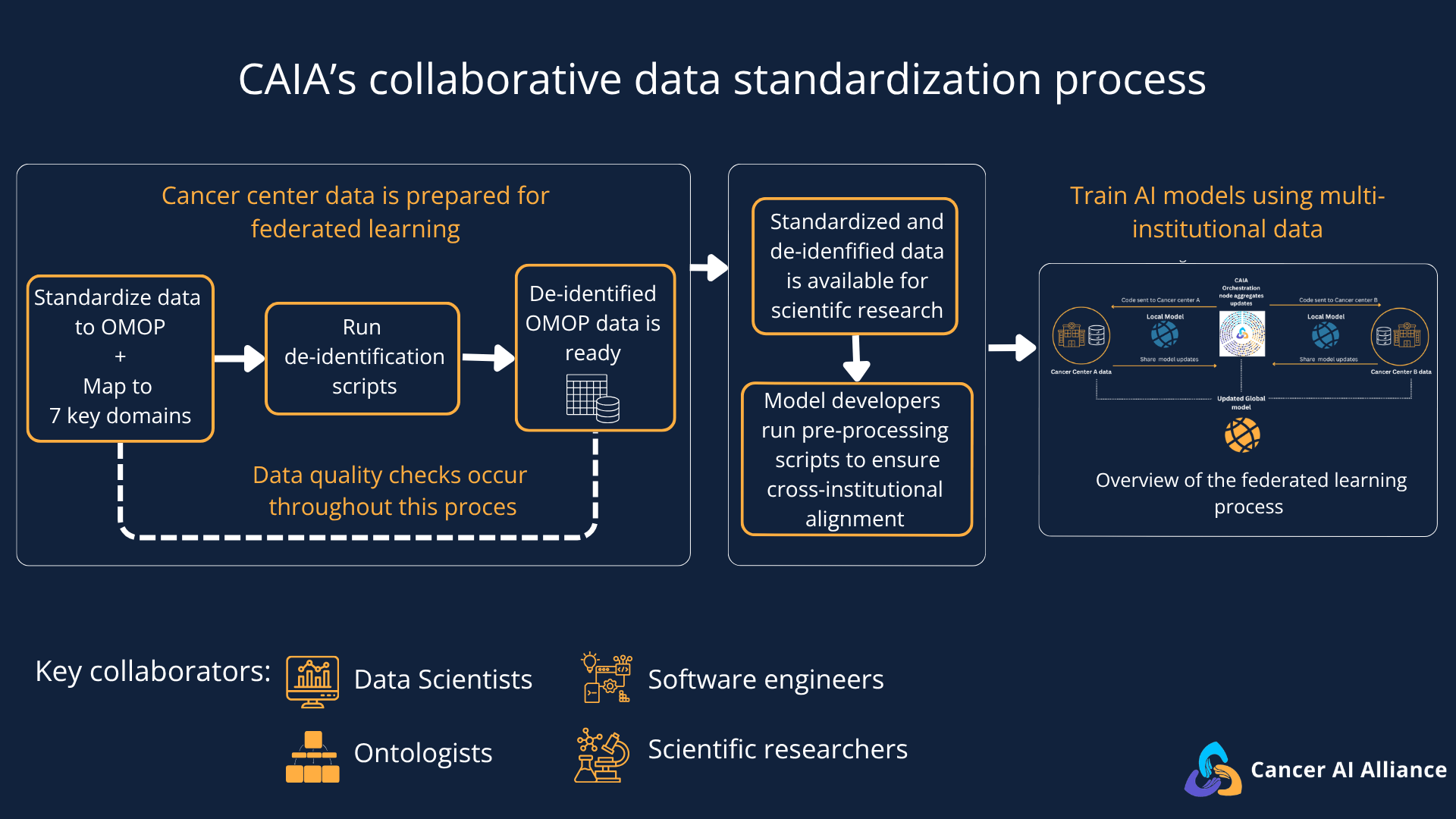
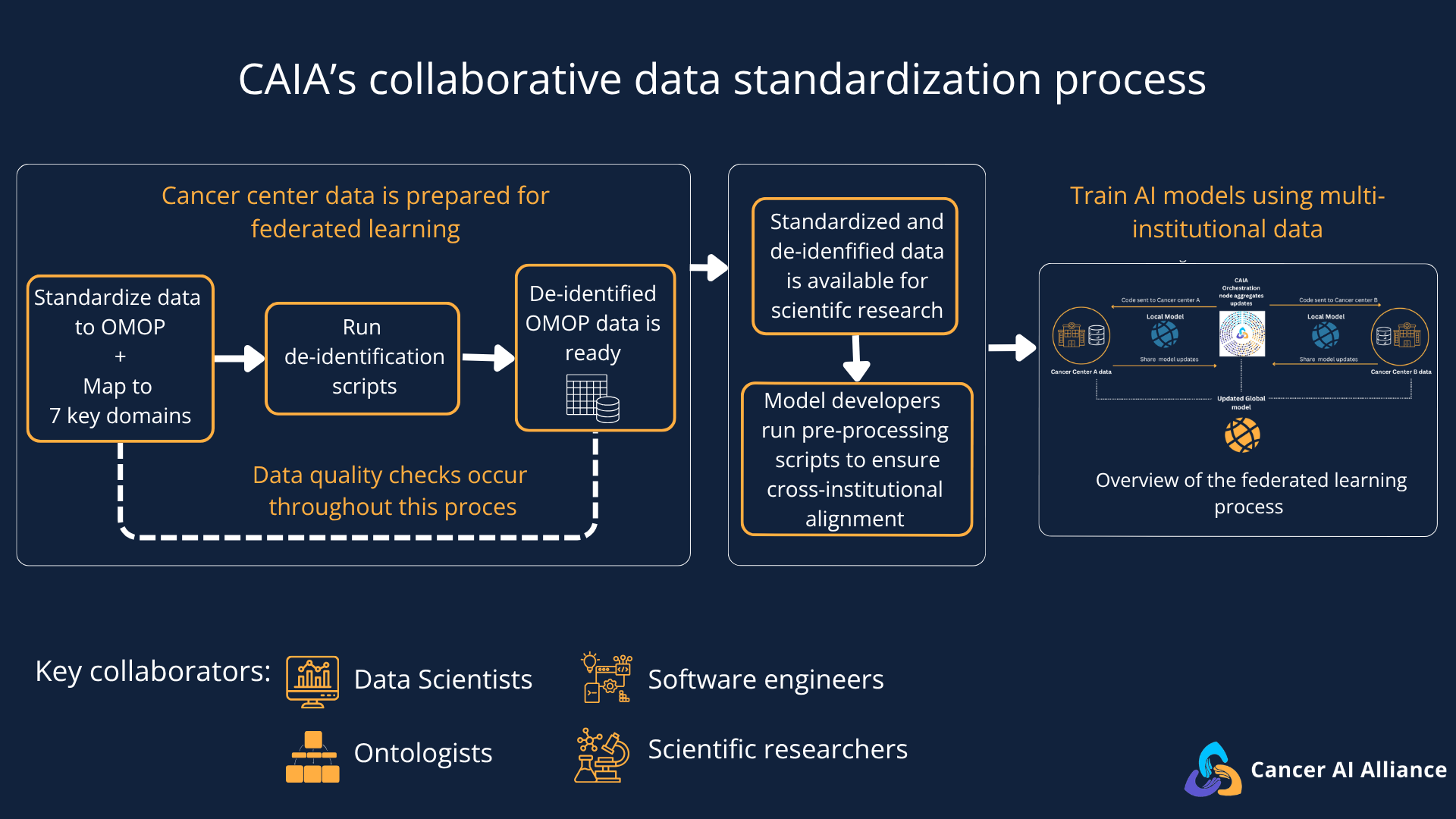
CAIA’s Gen 1 dataset comprises de-identified clinical data, a crucial regulatory requirement. However, the de-identified data structure and format need to be uniform and accessible for researchers to work seamlessly, especially because each cancer center has its own systems for maintaining its data and recording patient experiences.
Mapping these individualized data systems to a consistent, collaborative, multi-site model required a massive, coordinated effort. The teams achieved this by aligning to an open-source CDM called OMOP to standardize seven key structured clinical domains, including conditions and procedures. This collaborative alignment allowed data teams to jointly solve data inconsistencies and share tools, transforming their health records into a structured, common format. As Dr. Michele Waters, Senior Computational Biologist at Memorial Sloan Kettering Cancer Center (MSK), explains:
“Each institution using the same data preparation standards gives researchers more faith that the models they develop are seeing the right data, which will impact their downstream analysis, research, and conclusions they make.”
This standardization of structured data was a critical step required to support CAIA’s first wave of 8 clinical and AI pilot projects. Because the data is standardized across institutions, researchers can now train models to identify rare clinical patterns — such as predicting metastatic bone fractures or early-stage prostate cancer lineage plasticity — that are difficult to study effectively within a single cancer center.
While this first phase is limited to structured data, the standardized OMOP structure serves as the “technical backbone” that will allow CAIA to securely connect even more complex, multimodal data types — like medical imaging and genomic sequencing — across the network in the future.
Data standardization work is highly interdisciplinary
Preparing biomedical data for AI is not automated at CAIA. Up to 90% of data teams’ time at participating cancer centers is dedicated to the largely unseen work of data cleaning, and then eventually preprocessing and validation. Each cancer center ensures that the people preparing the data understand the clinical context of the records they are standardizing.
While data standardization work takes place entirely inside each cancer center, those doing the work meet regularly as part of a working group where shared lessons can be exchanged for the benefit of the entire Alliance. At Memorial Sloan Kettering, this work is powered by a small, dedicated team including clinical data mapping experts (called ontologists), software engineers, analysts, data engineers, and data scientists.
To bridge the gap between technical departments and active scientific research teams, Dr. Michele Waters helps coordinate the release, validation, and preprocessing of new data for MSK and other participating cancer centers. She also ensures that software engineers understand the intent of the research, and she works closely with ontologists and lead model developers, providing the MSK team with searchable concept-mapping tools to easily locate and verify the standardized data fields they need for model training.
Since CAIA’s federated learning approach prevents researchers from directly viewing another institution's datasets, internally the MSK team uses “human-curated, standardized datasets as a benchmark to see how well [their] models are performing.” By validating local models against these benchmarks, the team can test if the resulting AI model will be accurate, safe, and robust.
Data standardization allows for traceability
Monica Gerber, a data scientist at Fred Hutch Cancer Center, points out that since this intensive standardization work happens locally at each institution, the teams retain complete visibility into where their data came from. If a clinical data point looks anomalous or inconsistent, these in-house teams have the resources to notice the error, trace it, and resolve it. As she explains, the advantage of standardizing data locally is:
“The institution that generated the data is still involved in how that data is used and interpreted … maintaining the original link to the cancer center [means] you can still have that understanding of the context in which the data was generated.”
This localized data stewardship is also key to navigating the tension between data usability and strict patient privacy. To protect patient identities while preserving the clinical context, all protected health information is removed, and local teams consistently randomize and shift dates relating to treatments or procedures. This preserves the relative sequence of timeline events, allowing researchers to accurately study progression-free survival and time-dependent clinical outcomes, without exposing identifiable data.
If you’d like to learn more about CAIA, subscribe to our newsletter for updates and follow us on LinkedIn and X.